
The Backend Bottlenecks That Kill Task Apps First

The Backend Bottlenecks That Kill Task Apps First
Last Updated on January 7, 2026
Key Takeaways
What You’ll Learn
- Task apps fail mainly due to backend bottlenecks, not bad ideas or poor marketing.
- Real-time matching, payments, and notifications stress backend systems the most.
- Slow backend performance directly reduces trust, engagement, and repeat usage.
- Early backend architecture decisions define long-term scalability and costs.
- Founders must treat backend planning as a business decision, not just technical work.
Stats That Matter
- 53% of users leave apps that take more than three seconds to respond.
- A 100ms delay can reduce conversions by up to 7%.
- Nearly half of users abandon platforms after payment failures.
- Proper caching can reduce backend load by up to 80%.
- Downtime can cost businesses thousands of dollars per minute.
Real Insights
- Fast job matching builds trust and increases task completion.
- Reliable payouts keep service providers active and loyal.
- Real-time systems must be event-driven, not request-heavy.
- Monitoring prevents public failures by catching issues early.
- Growth-ready backends save money by avoiding rebuilds later.
The Backend Bottlenecks That Kill Task Apps First
You didn’t build a task app to babysit servers.
You built it to move fast, win users, and grow.
But here’s the part most founders don’t hear early enough: task apps don’t die because of bad ideas. They die because the backend can’t keep up. One slow job match. One delayed notification. One payout hangs for five seconds too long. Users feel it. Providers leave. Trust breaks.
On-demand service marketplaces like TaskRabbit are backend-heavy by design. They run on real-time availability, location logic, matching engines, payment flows, and event-driven notifications – all firing at once. When that system is fragile, growth becomes a liability, not a win.
This guide breaks down the backend bottlenecks that kill task apps first – before reviews turn ugly and CAC explodes. No jargon. No theory. Just the real issues founders face after launch, and how smart teams engineer for scale from day one.
If you’re planning to launch an on-demand marketplace – or already live – this is the part you can’t afford to skip.
Why Most Task Apps Fail After Launch (Not Before)
Most task apps don’t fail at the idea stage.
They fail when real users show up.
During demos, everything looks fine. Jobs post. Providers respond. Payments go through. But once usage increases – even slightly – the cracks begin to show. Pages load more slowly. Jobs take longer to match. Notifications arrive late. Support tickets increase.
This is where founders are caught off guard.
The problem is not demand.
The problem is that backend systems built for demos are suddenly expected to handle real-world behavior: concurrent users, peak-hour spikes, unreliable networks, and payment retries.
What founders usually see first:
- Jobs are taking longer to appear
- Providers missing requests
- Users abandoning flows mid-booking
What’s actually happening:
- Backend bottlenecks are stacking up silently
- Systems designed for “happy paths” are failing under pressure
The result is predictable. Growth stalls. Trust erodes. Churn rises. Marketing spend goes to waste.
Backend performance is not a technical detail.
In task apps, it is a direct driver of revenue, retention, and brand credibility.
What Makes Task Apps Backend-Heavy by Nature
On-demand service marketplaces are fundamentally different from content apps or simple e-commerce platforms. They are coordination systems. Every action depends on multiple systems working together, in real time.
A single task request can trigger:
- Location checks
- Availability filters
- Matching logic
- Pricing calculations
- Notifications
- Payment authorization
- Status updates across multiple users
All of this happens within seconds. If even one layer slows down, the experience breaks.
Why TaskRabbit-like platforms stress the backend
- Real-time matching: Users expect instant results, not refresh cycles
- Two-sided interactions: Customer actions affect providers immediately
- State-heavy workflows: Jobs move through multiple statuses
- Time sensitivity: Delays reduce acceptance rates
- Trust dependency: Payments and payouts must feel instant and reliable
Why MVP testing hides these issues
- Low user concurrency
- Artificially clean data
- No peak-hour behavior
- Limited edge cases
Founders often assume, “We’ll optimize later.”
In reality, retrofitting scalability into a live task app is expensive, risky, and disruptive.
Backend architecture decisions made early determine whether growth is smooth – or painful.
Backend Bottleneck – 1: Slow Job Matching Logic
Slow job matching is one of the earliest and most damaging backend bottlenecks in task apps. Even a 100-millisecond delay can reduce conversions by up to 7%, which is why slow matching and real-time backend delays quietly erode marketplace performance.
From a user’s perspective, this feels like:
- “No providers available”
- “The app is broken”
- “I’ll try another platform”
From the provider’s side:
- Jobs arrive too late
- Notifications feel random
- Earnings become unpredictable
Why job matching slows down
Common technical causes include:
- Inefficient database queries
- No indexing on location or skill filters
- Overloaded matching rules running synchronously
- Matching logic recalculated repeatedly instead of cached
These issues compound as the platform grows.
Business impact of slow matching
| Issue | Direct Impact |
| Delayed matches | Higher user drop-off |
| Late notifications | Lower job acceptance |
| Inconsistent availability | Provider frustration |
| System strain | Higher infrastructure costs |
Why this matters to founders
In on-demand marketplaces, speed equals trust.
If users feel uncertainty at the moment of intent, they leave. If providers miss opportunities, they disengage.
Fast, predictable job matching is not an optimization.
It is a core business requirement.
Backend Bottleneck – 2: Database Overload as Users Grow
Early traction is exciting.
It’s also where many task apps quietly start to break.
At low usage, most databases perform well enough. But as users grow – more tasks, more providers, more status updates – the same database suddenly becomes the system’s biggest constraint.
Founders usually notice symptoms before causes:
- Pages are loading more slowly during busy hours
- Tasks are not updating in real time
- Data appears inconsistent across users
What’s happening underneath is simple. The database is doing too much, too often.
Common causes of database overload
- Single database handling both reads and writes
- No separation between transactional and analytical queries
- Excessive joins on frequently accessed tables
- Repeated queries for the same data without caching
In task apps, almost every user action hits the database. When that database isn’t designed for concurrency, performance drops fast.
The risk for founders is not just speed. It’s reliability. Once users see inconsistent behavior, confidence drops – and regaining it is expensive.
Backend Bottleneck – 3: Real-Time Location & Availability Failures
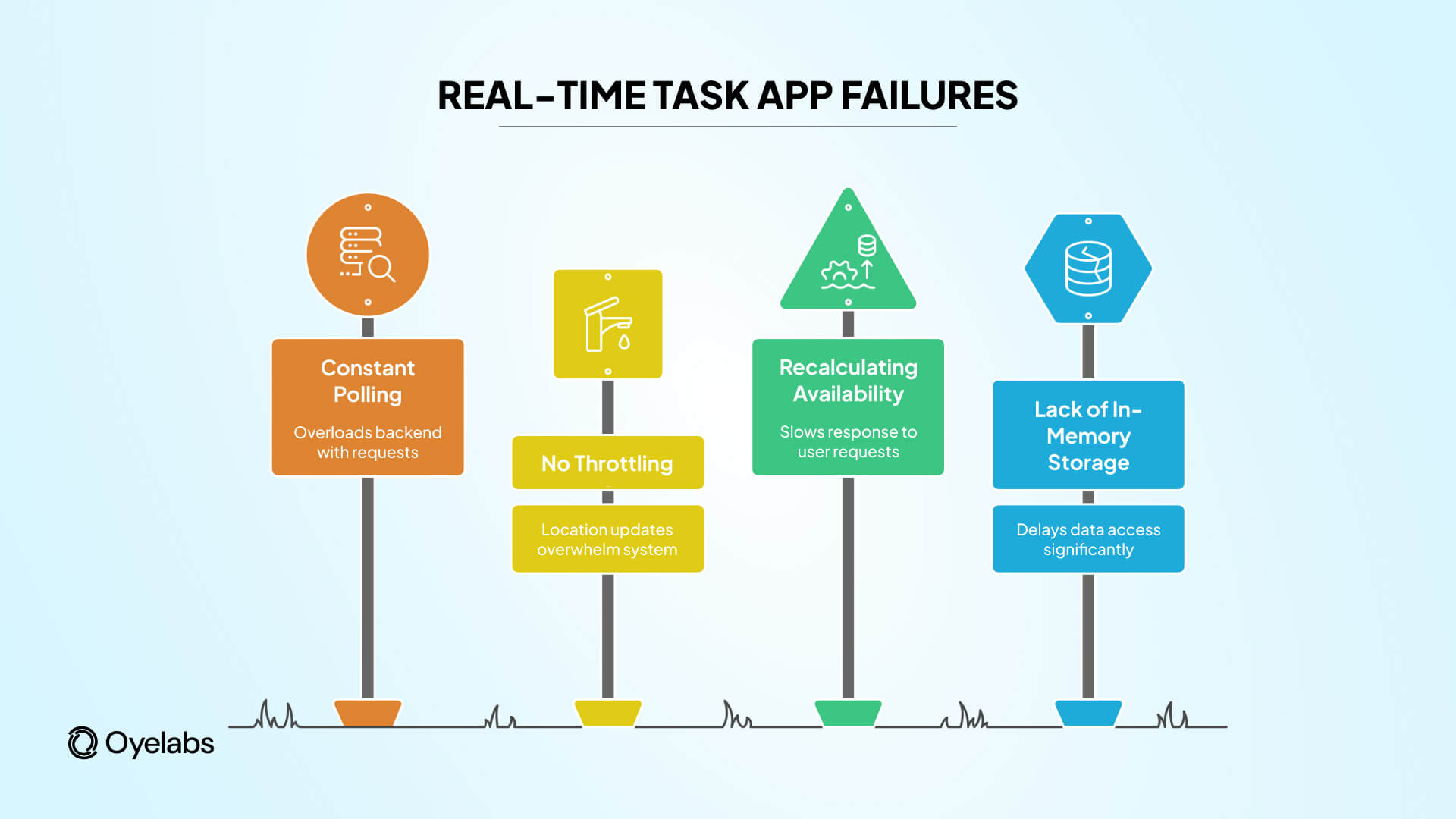
Real-time functionality is not a “nice to have” in task apps. It’s the product.
Users expect to see available providers now, not 10 seconds later. Providers expect job requests that reflect their current location and status. When this fails, the platform feels unreliable – even if everything else works.
Why real-time systems fail under load
- Constant polling instead of event-driven updates
- No throttling or batching of location updates
- Backend recalculating availability on every request
- Lack of in-memory storage for fast access
As traffic increases, these systems don’t degrade gracefully. They collapse suddenly.
What founders experience
- Providers shown as “available” when they are not
- Jobs sent to the wrong radius
- Customers seeing empty results despite active supply
These issues directly affect marketplace balance. Demand and supply stop meeting efficiently, and both sides blame the platform.
Real-time systems must be engineered for scale from day one. Retrofitting them later is one of the most costly backend fixes.
Backend Bottleneck – 4: Notification & Communication Delays
In task apps, notifications are not engagement tools.
They are revenue triggers.
A job request notification that arrives late might as well not arrive at all. Every second of delay reduces acceptance probability, especially in competitive marketplaces.
Where notification systems break
- Notifications sent synchronously with user actions
- Overloaded message queues
- No retry or fallback logic
- Single-channel dependency (push only, no SMS/email backup)
These failures don’t always show up in testing. They appear under load, during peak hours, or when external services slow down.
The compounding business effect
- Providers miss jobs
- Jobs expire unaccepted
- Customers re-post or leave
- Support volume increases
The worst part is that these issues feel random to users. Random failures destroy trust faster than consistent ones.
Reliable task platforms treat notifications as asynchronous, fault-tolerant systems – not as simple API calls.
Backend Bottleneck – 5: Payment & Payout Processing Breakdowns
If there is one backend failure that damages a task app faster than any other, it is payments.
Users might tolerate a slow screen. Providers will not tolerate delayed or missing payouts. The moment money feels unreliable, trust disappears.
Where payment systems usually fail
- Payment flows tightly coupled to user actions
- No asynchronous handling of gateway responses
- Webhooks not processed reliably
- Missing retry and reconciliation logic
- Payouts triggered without proper state validation
In early builds, payments are often treated as a linear process: user pays, provider gets paid. In reality, payment systems are event-driven, error-prone, and asynchronous by nature.
What founders experience
- “Pending” payments that never resolve
- Duplicate charges or missed payouts
- Providers contacting support instead of accepting jobs
- Manual intervention becoming routine
Payment bottlenecks don’t just slow growth. They create operational chaos. Support costs rise, disputes increase, and platform reputation suffers.
Strong task apps isolate payment logic, queue critical events, and treat failures as expected – not exceptional.
Backend Bottleneck – 6: No Caching Strategy (Everything Hits the Server)
One of the simplest – and most expensive – mistakes in early task apps is skipping caching altogether.
When every request goes straight to the database, performance degrades quickly. As traffic grows, infrastructure costs rise while speed drops.
Common caching gaps
- Frequently accessed data fetched repeatedly
- No in-memory store for availability or pricing data
- User session data stored inefficiently
- Backend recalculating identical responses for each request
Without caching, the backend works harder than necessary. With caching, the system responds faster using fewer resources.
Why this matters to founders
Caching directly impacts:
- App response time
- Server load
- Cloud infrastructure costs
- Ability to handle traffic spikes
Founders often associate caching with “optimization later.” In reality, caching is a stability layer. It protects the system when growth arrives sooner than expected.
Backend Bottleneck – 7: Monolithic Architecture That Can’t Scale
Many task apps start with a monolithic backend. It feels faster and cheaper at the beginning. Over time, it becomes a constraint.
When everything lives in one codebase and one deployment pipeline, small changes carry big risks.
Problems founders face with monoliths
- One bug can break the entire platform
- Feature updates require full redeployments
- Scaling one component means scaling everything
- Development slows as complexity increases
This becomes especially painful in task apps, where booking, payments, notifications, and real-time updates evolve at different speeds.
Why does this become a growth blocker
As the platform grows:
- Teams become afraid to ship updates
- Fixes take longer than expected
- Downtime risk increases with every release
A modular or service-oriented backend allows platforms to scale selectively and evolve safely. Founders who plan for this early avoid expensive rewrites later.
Backend Bottleneck – 8: No Load Handling for Peak Demand
Many task apps don’t fail gradually. They fail suddenly – right when traction hits.
A marketing campaign performs well. A city launches. A seasonal spike arrives. The backend, designed for average traffic, gets overwhelmed by peak demand.
Why peak load breaks task apps
- Single-server or single-instance deployments
- No load balancing across services
- Backend processes running synchronously
- No rate limiting or traffic control
When traffic spikes, requests queue up. Response times increase. Timeouts follow. To users, it looks like downtime – even if servers are technically “up.”
The business cost of poor load handling
- Jobs fail to post during high-intent moments
- Providers stop trusting notifications
- Paid marketing traffic is wasted
- Brand perception takes a hit early
Peak demand is not an edge case.
In on-demand platforms, peaks define success. Backend systems must be built to absorb growth, not collapse under it.
The Silent Killer: Poor Backend Monitoring & Logging
One of the most damaging backend bottlenecks is also the least visible: lack of monitoring.
Founders often learn about issues only after users complain. By then, damage is already done.
What’s usually missing
- Real-time performance metrics
- Error tracking across services
- Visibility into failed jobs or payments
- Alerts before users notice problems
Without monitoring, teams operate reactively. Every issue becomes urgent. Root causes take longer to identify, and fixes are rushed.
Why this matters to leadership
For founders, monitoring is not a technical luxury. It is an operational control system.
Strong backend monitoring allows teams to:
- Detect bottlenecks before they escalate
- Understand usage patterns as the platform grows
- Make informed scaling decisions
- Protect user trust quietly and consistently
The most reliable task platforms rarely surprise their users – because issues are handled before they surface.
How One Founder Avoided These Backend Bottlenecks with Oyelabs
One founder approached Oyelabs after realizing their initial prototype could not support real user demand. Instead of rebuilding later, they launched a TaskRabbit-like on-demand service marketplace with a scalable backend from the start – designed for real-time matching, modular services, and peak traffic handling. The result was a smoother launch, faster task fulfillment, and consistent provider engagement. As usage grew, the platform handled traffic spikes without disruption, helping the founder improve impressions, boost user trust, and establish early brand credibility in their market rather than fighting performance issues post-launch.
Build vs. Buy: Why Backend Architecture Decisions Decide Survival
Most founders don’t start by asking, “Should we build everything from scratch?”
They start by asking, “How fast can we launch?”
That question matters – but only if the backend can survive success.
The hidden risk of building from scratch
Custom builds often look flexible on paper, but early-stage teams usually under-engineer the backend:
- Core systems are tightly coupled
- Scalability is postponed
- Performance assumptions are optimistic
- Real-world load is underestimated
When growth arrives, teams are forced into expensive rewrites – right when focus should be on users and revenue.
Where white-label plus customization works better
For task apps and on-demand service marketplaces, a proven backend foundation combined with targeted customization often delivers better outcomes:
- Faster time to market
- Pre-tested scalability patterns
- Predictable performance under load
- Lower long-term technical debt
The decision is not “build vs. buy.”
It is build everything now vs. build what actually differentiates you.
Founders who choose wisely protect both capital and momentum.
What a “Growth-Ready” Backend Looks Like for Task Apps
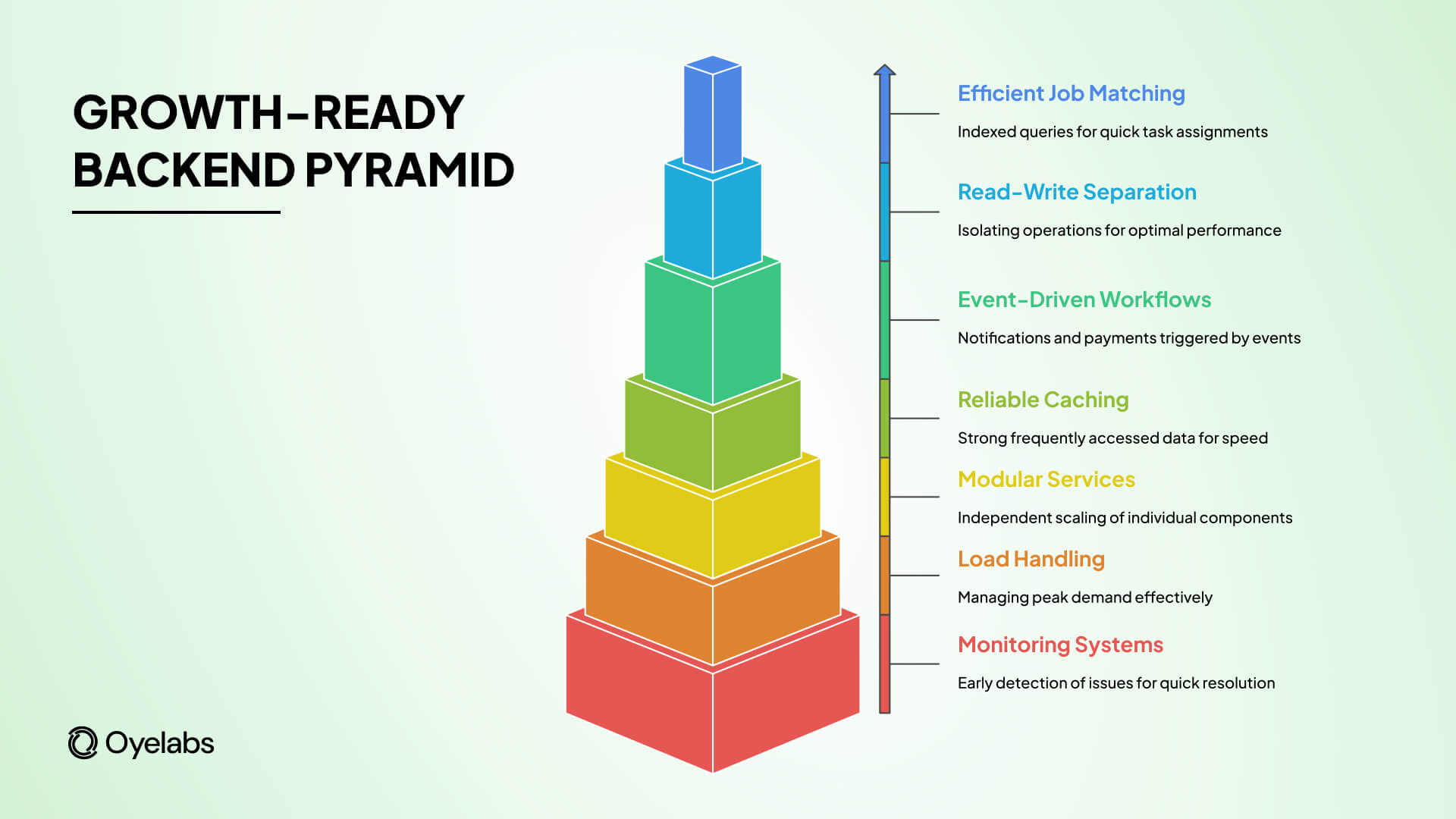
A growth-ready backend is not about overengineering.
It’s about removing single points of failure before they matter.
At a minimum, task apps built to scale should include:
- Efficient job matching logic with indexed queries
- Separation between read-heavy and write-heavy operations
- Event-driven workflows for notifications and payments
- Reliable caching for frequently accessed data
- Modular services that can scale independently
- Load handling for peak demand, not just average traffic
- Monitoring systems that surface issues early
This is not a wishlist.
It is the baseline required to support real usage without constant firefighting.
Founders who validate these elements before launch spend less time fixing issues and more time growing the marketplace.
Final Takeaway
In on-demand service marketplaces, backend performance is not a technical concern – it is a leadership concern.
Slow matching hurts conversions.
Payment delays destroy trust.
Downtime erases marketing gains.
Every backend bottleneck eventually shows up as a business problem.
Founders who succeed don’t wait for scale to force better decisions. They design for growth from the beginning – using systems that can handle real users, real traffic, and real money.
That is why many early-stage founders choose partners like Oyelabs – to launch TaskRabbit-like platforms with backend architecture built for performance, reliability, and long-term scale, not just demos.
Because in this space, the apps that win aren’t always the ones with the best idea.
They’re the ones whose backend doesn’t break first.
FAQs
Q1. Why do TaskRabbit-like apps fail after launch?
A: They fail due to slow backends, poor scalability, payment delays, and unreliable real-time systems.
Q2. What is the biggest backend challenge in task apps?
A: Real-time job matching under load is the most common and damaging backend challenge.
Q3. Is backend scalability important at MVP stage?
A: Yes, early backend decisions determine whether growth becomes smooth or painfully expensive.
Q4. Can non-technical founders manage backend risks?
A: Yes, by using proven architectures and experienced development partners instead of rebuilding later.




