
A Comprehensive Guide to Developing an AI Transformer Model

A Comprehensive Guide to Developing an AI Transformer Model
Last Updated on March 19, 2025
Since its introduction in the seminal paper “Attention is All You Need,” the Transformer model has transformed AI, particularly in natural language processing (NLP). Today, over 80% of state-of-the-art NLP models are based on Transformer architectures, driving innovations in chatbots, translation, and content generation. BERT, for example, achieved an 80.4% accuracy on the GLUE benchmark, significantly outperforming previous models. Unlike traditional RNNs and LSTMs, Transformers use self-attention mechanisms for parallel processing, improving efficiency and capturing long-range dependencies.
.Their adoption extends beyond NLP, powering breakthroughs in computer vision and protein structure prediction. This guide provides a comprehensive roadmap for developing an AI Transformer model, covering key concepts, implementation strategies, and optimization techniques to build high-performance AI applications.
Understanding Transformer Models
The Evolution of AI Models
Before the advent of Transformer models, Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) were the primary architectures employed in natural language processing (NLP). However, these models exhibited several notable limitations:
- Vanishing Gradient Problem: RNNs often struggled to retain information over long sequences due to diminishing gradients, making it challenging to learn long-range dependencies.
- Sequential Processing: RNNs and LSTMs process sequences token by token, limiting parallelization and increasing training times. This sequential nature can lead to longer training durations, especially with large datasets.
- Difficulty in Capturing Long-Range Dependencies: Traditional RNNs often struggle with the vanishing gradient problem, making it challenging to learn long-term dependencies.
The introduction of the Transformer model addressed these challenges by eliminating recurrence and leveraging self-attention mechanisms. This innovation led to several significant advancements:
- Faster Training: Transformers process entire sequences in parallel, significantly reducing training times compared to LSTMs. This parallelism allows for more efficient utilization of computational resources.
- Enhanced Context Retention: The self-attention mechanism enables models to capture dependencies across long sequences more effectively, improving performance in tasks requiring understanding of long-range context.
- State-of-the-Art Performance: Transformer-based models like BERT have achieved remarkable results on NLP benchmarks. For instance, BERT has demonstrated strong performance on the Stanford Question Answering Dataset (SQuAD), a benchmark for machine reading comprehension.
These advancements have positioned Transformers as foundational models in modern NLP applications, powering technologies such as chatbots, machine translation systems, search engines, and text generation tools.
Components of a Transformer
The Transformer model, introduced in the “Attention is All You Need” paper, consists of an encoder-decoder architecture designed to process sequential data efficiently. Unlike traditional models, it eliminates recurrence and relies on self-attention and parallel processing, making it significantly faster and more effective for handling long-range dependencies.
Encoder and Decoder Structure
- Encoder: Processes the input sequence and generates contextual representations.
- Decoder: Uses the encoder’s output and generates the final sequence step by step.
Each consists of multiple layers, and within each layer, there are core components that enable the Transformer’s high performance.
Self-Attention Mechanism
Self-attention is the core feature of Transformers, allowing them to weigh the importance of different words in a sentence relative to each other. Instead of processing inputs sequentially like RNNs, Transformers examine the entire sequence simultaneously. This helps retain meaning over long distances and improves understanding in complex NLP tasks like machine translation and summarization.
For example, in the sentence:
“The bank approved my loan because it had great financial records.”
A traditional model might struggle to determine whether “it” refers to the bank or loan. Self-attention helps the model establish that “it” is more related to “bank”, improving contextual comprehension.
Multi-Head Attention
Instead of using a single attention function, multi-head attention applies multiple attention layers in parallel. Each layer captures different types of relationships between words—such as syntactic structure, word meaning, or contextual nuances—making the model more robust.
This mechanism significantly improves Transformers’ ability to:
- Capture multiple relationships in a sentence simultaneously.
- Reduce reliance on word position and order.
- Improve accuracy in tasks like question-answering and language modeling.
Feedforward Layers
After self-attention, the model applies feedforward layers, which transform the extracted information into a richer representation. These layers consist of fully connected neural networks that refine the understanding of the input before passing it to the next stage.
Key benefits include:
- Adding non-linearity, making the model capable of learning complex patterns.
- Enhancing expressiveness, allowing the model to generate meaningful responses.
Positional Encoding
Because Transformers process all words in parallel (instead of sequentially like RNNs), they need a way to understand the order of words in a sentence. Positional encoding helps the model retain word order by adding unique position-based signals to each word’s representation.
For example:
- The model distinguishes between “The cat chased the dog.” and “The dog chased the cat.” despite both sentences containing the same words.
- It helps in translation tasks where word order varies between languages.
By combining positional encoding with self-attention, Transformers can efficiently process sequences without losing the structure of the sentence.
Also Read: How to Build an AI Model?
Step-by-Step Implementation of a Transformer Model
Transformers are the backbone of modern deep learning applications, powering models like BERT and GPT. They rely on self-attention mechanisms and feedforward neural networks to process sequential data efficiently. In this guide, we will walk through the implementation of a Transformer model using PyTorch.
Import Libraries
To begin, we import the necessary libraries:

torchandtorch.nnprovide the tools to define and train deep learning models.torch.optimis used for optimization (gradient descent, Adam, etc.).numpyis used for numerical operations (e.g., square root calculations).
Scaled Dot-Product Attention
Attention is a mechanism that enables the model to focus on different parts of the input sequence dynamically. The Scaled Dot-Product Attention computes attention scores using the following formula:
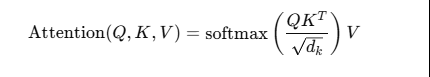
Where:
- QQ (Query): The current token’s representation.
- KK (Key): The representations of all tokens in the sequence.
- VV (Value): The actual values that will be weighted by attention scores.
- dkd_k is the dimension of the key vectors. Scaling by dk\sqrt{d_k} stabilizes gradients.
Implementation:
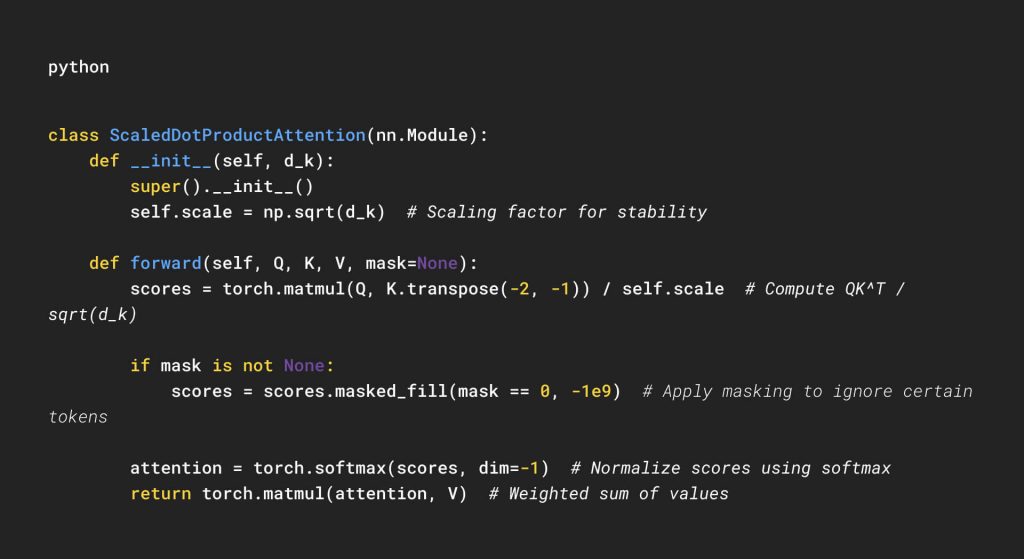
This module:
- Computes attention scores.
- Applies masking to prevent attending to certain positions (e.g., padding).
- Applies softmax to generate attention weights.
- Uses these weights to compute the final representation of
V.
Multi-Head Attention
A single attention mechanism may not be sufficient to capture different aspects of relationships between words. Multi-Head Attention enables the model to attend to different parts of the input using multiple sets of Queries, Keys, and Values.
Steps:
- Linear transformations: Convert the input into multiple Query, Key, and Value vectors (one for each attention head).
- Apply Scaled Dot-Product Attention in parallel.
- Concatenate the results and project back to the original dimension.
Implementation:
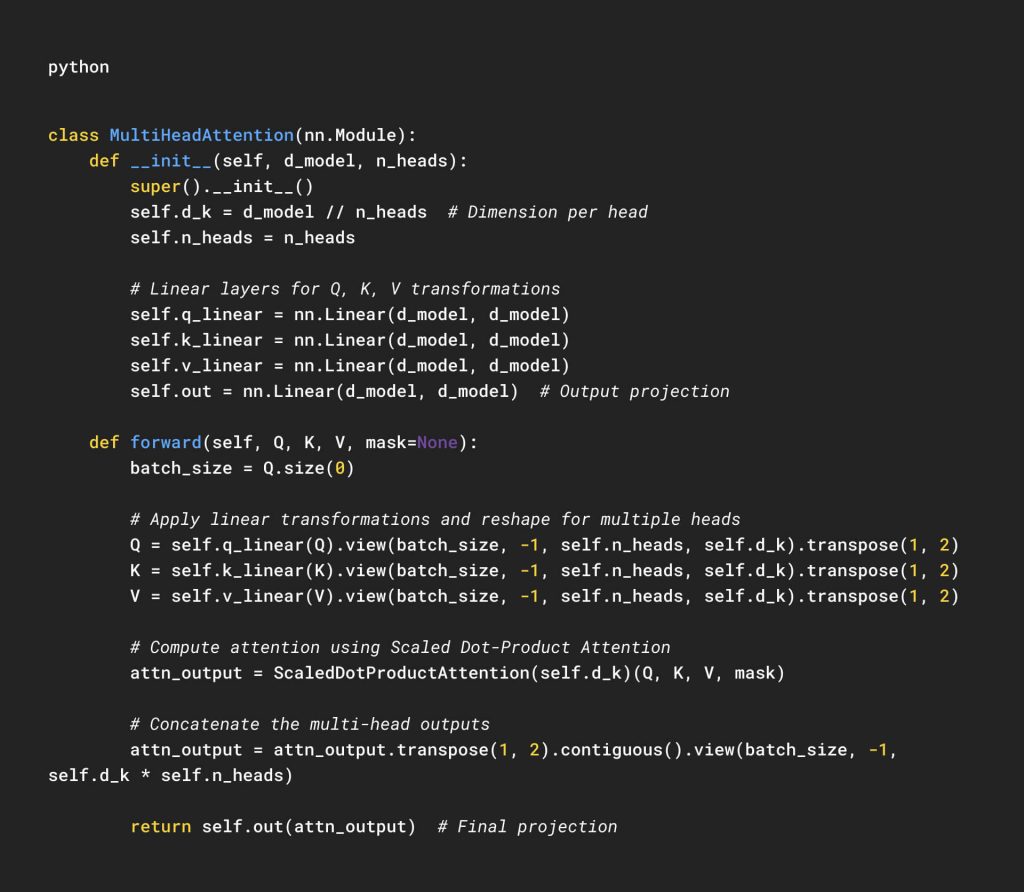
This module:
- Splits the input into multiple heads.
- Applies attention to each head independently.
- Concatenates and projects the results back to the original dimension.
Position-Wise Feedforward Network
Each Transformer layer includes a Feedforward Network (FFN), which consists of two linear layers with a ReLU activation function:
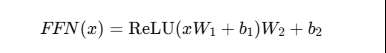
This helps in non-linearity and feature transformation.
Implementation:
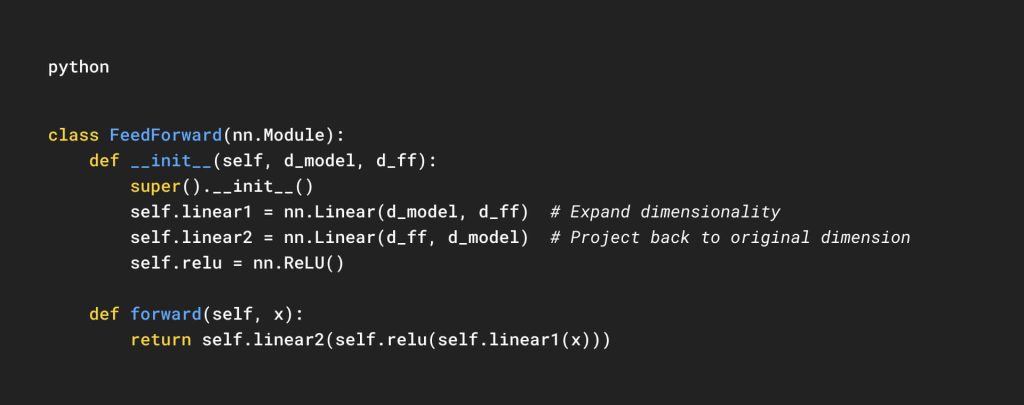
This module:
- Expands the representation (
d_model→d_ff). - Applies a non-linear transformation (
ReLU). - Projects back to
d_model.
Encoder Layer
Each Transformer encoder consists of:
- Multi-Head Attention (to capture dependencies across tokens).
- Layer Normalization (to stabilize training).
- Feedforward Network (to transform representations).
- Residual Connections (to preserve gradients).
Implementation:
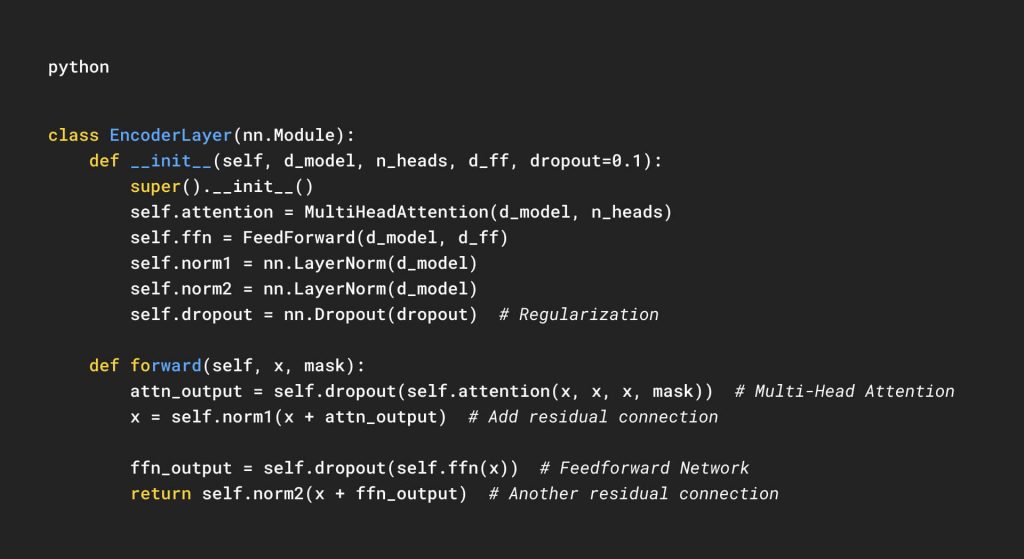
This module:
- Computes self-attention over the input sequence.
- Normalizes and adds residual connections.
- Applies a feedforward network.
- Uses dropout for regularization.
Training the Transformer Model
Dataset Preparation:
Before training begins, the dataset needs to be processed and tokenized. Unlike traditional models, Transformers require input sequences to be structured properly:
- Tokenization: Converts text into numerical tokens using a predefined vocabulary. Methods like Byte-Pair Encoding (BPE) and WordPiece are commonly used.
- Padding & Truncation: Since Transformer models require fixed-length sequences, shorter texts are padded, and longer ones are truncated to fit within a specified limit.
- Attention Masks: Indicate which tokens should be processed (real tokens) and which should be ignored (padding tokens).
- Encoding: Converts words into their respective numerical representations based on a pre-trained vocabulary.
A well-processed dataset ensures efficient learning and minimizes computational overhead.
Choosing a Loss Function:
The choice of loss function depends on the task:
- Classification Tasks: Cross-Entropy Loss is commonly used to measure the difference between predicted probabilities and actual labels.
- Language Modeling Tasks: Masked Language Modeling (MLM) loss is used, where certain words are masked and the model learns to predict them.
- Translation Tasks: Sequence loss functions, such as Negative Log-Likelihood, help optimize the model’s performance.
A task-specific loss function ensures that the Transformer learns meaningful representations rather than just memorizing data.
Optimizer and Learning Rate Scheduling
Training deep neural networks requires an efficient optimizer to update model weights. The AdamW optimizer, which includes weight decay, is preferred for Transformers.
Additionally, learning rate scheduling is crucial to stabilize training. A warmup strategy—increasing the learning rate initially and then decaying it over time—prevents instability and improves convergence. This technique was introduced in the “Attention Is All You Need” paper and is widely adopted in Transformer training.
Also Read: Optimization Tips for AI Models
Training Loop and Weight Updates:
Once the dataset, loss function, and optimizer are set up, the model undergoes multiple epochs of training. The training loop involves:
- Processing Batches: Splitting the dataset into smaller subsets for efficient learning.
- Forward Pass: Feeding inputs into the model to generate predictions.
- Loss Calculation: Comparing predictions to actual labels to compute errors.
- Backpropagation: Adjusting model weights to minimize the loss.
- Optimization: Updating parameters using the optimizer.
- Learning Rate Adjustments: Modifying the learning rate dynamically to improve learning efficiency.
Repeating this process over multiple epochs ensures the Transformer learns complex patterns in the data.
Optimizations and Best Practices
Using Pre-Trained Models
Training a Transformer from scratch requires enormous computational resources, extensive datasets, and significant time. Instead, leveraging pre-trained models such as BERT, GPT, T5, and RoBERTa can save time and improve performance.
Why Use Pre-Trained Models?
- Reduced Training Time: Instead of training from scratch, fine-tuning a pre-trained model significantly accelerates the process.
- Improved Performance: Pre-trained models have already learned language structures and semantic representations, making them highly effective for downstream tasks.
- Lower Resource Consumption: Since the model has already been trained on vast corpora, fine-tuning requires fewer computational resources.
Fine-Tuning Pre-Trained Transformers
Fine-tuning allows pre-trained models to adapt to domain-specific tasks by updating their weights on a smaller, labeled dataset. The process includes:
- Freezing Earlier Layers: Keeping the initial layers unchanged and training only the final layers helps retain general linguistic knowledge while adapting to specific tasks.
- Task-Specific Training: Fine-tuning on specialized datasets, such as medical texts or legal documents, ensures better contextual understanding in specific domains.
- Gradual Unfreezing: Sequentially unfreezing layers and training them step-by-step prevents catastrophic forgetting, where the model loses its prior knowledge.
Pre-trained models make NLP applications more accessible by reducing the need for extensive labeled datasets and high-performance computing infrastructure.
Data Augmentation in NLP
Unlike computer vision, where image transformations like rotation and flipping enhance dataset diversity, NLP data augmentation is more challenging because minor changes in text can significantly alter meaning. However, several augmentation techniques help improve training data quality and model generalization.
Effective NLP Data Augmentation Methods
1. Back-Translation
A sentence is translated into another language and then back into the original language to generate variations. Example:
- Original: The weather is nice today.
- Translated to French: Il fait beau aujourd’hui.
- Back to English: It is beautiful today.
This preserves meaning while introducing diverse sentence structures.
2. Synonym Replacement
Random words are replaced with their synonyms to generate varied training samples. Example:
- Original: The movie was fantastic.
- Augmented: The film was excellent.
This method prevents the model from becoming too dependent on specific word choices.
3. Random Deletion & Word Order Swapping
- Some words are randomly removed, or their order is slightly changed to create diverse training samples while preserving core meaning. Example:
- Original: He quickly finished his assignment.
- Augmented: He finished his assignment quickly.
By using these techniques, NLP models can generalize better and avoid overfitting on small datasets.
Regularization Techniques
Regularization is essential for preventing overfitting, ensuring that the Transformer model generalizes well to unseen data. Some of the most effective techniques include:
1. Dropout
- Randomly removes neurons during training, forcing the model to rely on multiple features rather than memorizing specific patterns.
- Helps improve robustness and reduces dependency on certain nodes.
2. Weight Decay (L2 Regularization)
- Adds a penalty to large weight values, preventing the model from over-relying on any single feature.
- Encourages simpler and more generalizable models.
3. Gradient Clipping
- Limits the maximum gradient value during backpropagation to prevent sudden large updates that could destabilize training.
- Useful for handling exploding gradients in deep networks.
These techniques help create more reliable Transformer models that maintain high performance across various datasets.
Monitoring Training Progress
Tracking key metrics is crucial for evaluating Transformer models and making necessary adjustments. The most commonly used evaluation metrics include:
1. Perplexity (PPL)
- Measures how well the model predicts sequences.
- Lower perplexity values indicate better performance, as the model assigns higher probabilities to correct predictions.
2. BLEU Score (Bilingual Evaluation Understudy)
- Used in machine translation to compare generated text with human-written translations.
- Measures the overlap between predicted and reference sentences.
3. Accuracy & F1 Score
- For classification tasks, accuracy measures overall correctness, while F1 Score balances precision and recall, ensuring robust performance assessment.
By continuously monitoring these metrics, developers can fine-tune hyperparameters, adjust model architecture, and improve training processes.
Build a Powerful AI Transformer Model with Oyelabs
Transformers have revolutionized AI, powering everything from chatbots to advanced language models. At Oyelabs, we help businesses and innovators develop and deploy high-performance Transformer models tailored to their unique needs. Whether you need to fine-tune existing models like BERT and GPT or build a custom AI solution from the ground up, our team ensures seamless integration, optimization, and scalability.
With expertise in deep learning, NLP, and AI-driven applications, we provide end-to-end development, from data preprocessing to model deployment. Let us help you harness the power of AI to drive innovation and efficiency in your business. Partner with Oyelabs today to build your AI-driven future. Contact us now!
Conclusion
Transformers have revolutionized artificial intelligence by overcoming the limitations of traditional sequence models. Their self-attention mechanism, parallel processing capabilities, and scalability have made them the foundation of modern NLP, powering applications in chatbots, machine translation, recommendation systems, and even computer vision. As AI continues to evolve, optimizing Transformer models with efficient architectures, pre-trained models, and advanced training techniques will be crucial for businesses aiming to stay ahead. Whether you’re developing custom AI solutions or fine-tuning existing models, leveraging Transformers effectively can unlock new possibilities in automation, personalization, and data-driven insights. By embracing this technology, organizations can build smarter, faster, and more adaptable AI systems to meet the demands of the future.
Also Read:



